
Bạn hiện tại đang sở hữu bao nhiêu dữ liệu cá nhân? Bạn có phải mua thêm “storage” để lưu trữ hình ảnh, video, thông tin của mình?
Hãy tưởng tượng vấn đề thiếu không gian lưu trữ đó được nhân lên gấp trăm, nghìn, thậm chí hàng triệu lần – đó chính là tình trạng thường nhật mà các doanh nghiệp phải đối mặt. Với việc dữ liệu tăng gấp đôi kích thước chỉ sau khoảng hai năm [1], khối lượng thông tin khổng lồ được tạo mỗi ngày này đã vượt xa sức chứa của một hệ thống lưu trữ văn phòng hay cơ sở dữ liệu ảo thông thường. Từ đó, thuật ngữ “dữ liệu lớn” (big data) ra đời.
Nếu vậy, làm thế nào mà cá nhân và doanh nghiệp có thể quản lý, bảo mật và khai thác hiệu quả lượng dữ liệu khổng lồ này?
Đọc thêm:7 ứng dụng phổ biến của công nghệ điện toán đám mây
Bài viết này sẽ giải thích các đặc điểm chính của dữ liệu lớn, đồng thời giới thiệu các giải pháp lưu trữ sẵn có và cách để thúc đẩy văn hóa dữ liệu trong doanh nghiệp.
Dữ liệu lớn là gì?
Dữ liệu lớn (big data) chỉ lượng dữ liệu khổng lồ đến mức khó tin, bao gồm dữ liệu có tổ chức và rời rạc, dung lượng có thể đạt đến petabyte (tương đương 1024 terabyte hay một triệu gigabyte) hoặc exabyte (một tỷ gigabyte). Việc xử lý một khối lượng lớn thông tin đòi hỏi những phương pháp chuyên biệt [2].
Dữ liệu có cấu trúc là bất kỳ thông tin nào được sắp xếp theo một định dạng tiêu chuẩn, cho phép tìm kiếm và phân tích dễ dàng. Ví dụ như từng dòng trong một bảng Excel. Ngược lại, dữ liệu phi cấu trúc không tuân theo bất kỳ mô hình dữ liệu nào và tồn tại dưới nhiều hình thức đa dạng. Ví dụ: văn bản, hình ảnh, âm thanh, video, v.v.
Bất kể ở dưới hình thức nào, mỗi mảnh dữ liệu đều có giá trị tiềm năng bởi nó chứa đựng những hiểu biết sâu sắc có thể hỗ trợ quá trình đưa ra quyết định.
Đọc thêm:4 bước để quản lý dữ liệu doanh nghiệp hiệu quả hơn
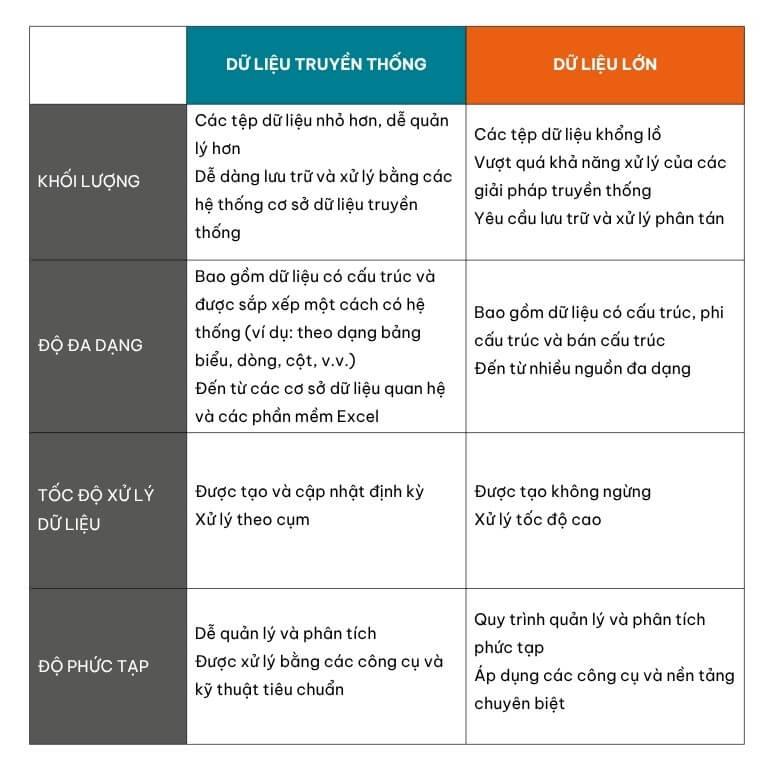
Những khác biệt chính giữa dữ liệu truyền thống và dữ liệu lớn
Phương pháp quản lý dữ liệu truyền thống sử dụng các cơ sở dữ liệu có cấu trúc để lưu trữ thông tin một cách có tổ chức trong các bản ghi, tệp tin, bảng biểu, v.v. Chúng ta sẽ thường gặp loại dữ liệu này nhất mỗi ngày như trong các báo cáo.
Mặt khác, dữ liệu lớn sở hữu một cấu trúc linh hoạt hơn, có thể được xem như “bản thiết kế” mô tả cách dữ liệu có thể được sắp xếp và liên kết với nhau. Điều này đồng nghĩa với việc dữ liệu lớn có thể “nhiễu” và đòi hỏi kiến thức chuyên sâu để sàng lọc và phân tích.
Tóm lại, sự khác biệt giữa dữ liệu truyền thống và dữ liệu lớn có thể được tóm tắt như sau:
Các ngành khác nhau dùng dữ liệu lớn như thế nào?
Các doanh nghiệp y tế tận dụng phân tích dữ liệu lớn để nghiên cứu các dữ liệu trong quá khứ nhằm phục vụ cho việc chẩn đoán bệnh và phát triển phát đồ điều trị tỉ mỉ, nhờ vậy rút ngắn các quy trình và kiểm tra không cần thiết.
“Gã khổng lồ bán lẻ” Amazon thu thập một lượng lớn dữ liệu về hành vi mua hàng, phương thức giao hàng và ưu tiên của khách hàng mỗi ngày. Nhờ đó, họ có thể đưa ra các gợi ý mua sắm cực kỳ cá nhân hóa đến từng khách hàng. Tương tự như vậy, Netflix và Spotify là những minh chứng rõ ràng cho việc ngành giải trí sử dụng phân tích dữ liệu lớn để đề xuất nội dung phù hợp với từng cá nhân.
Dữ liệu lớn được các ngân hàng và tổ chức tài chính khai thác để phát hiện sớm hành vi gian lận và rủi ro thông qua hành vi mua hàng của chủ thẻ tín dụng, từ đó cảnh báo các giao dịch đáng ngờ và cải thiện quy trình hoạt động.
Đọc thêm:5 cách tối ưu lợi ích Business Intelligence cho ngành khách sạn (P.1)
Ngành dự báo thời tiết cũng đã có những bước tiến vượt bậc nhờ dữ liệu lớn. Các nhà khí tượng phân tích dữ liệu từ vệ tinh và thông tin cảm biến để nghiên cứu quy luật của các thảm họa tự nhiên và đưa ra những dự báo thời tiết chính xác hơn.
Các cơ quan nhà nước như Cục Thuế và An sinh Xã hội phân tích dữ liệu lớn để phát giác những trường hợp gian lận thuế hoặc các yêu cầu trợ cấp khuyết tật giả mạo.

Lợi ích của dữ liệu lớn là gì?
Khi sử dụng các giải pháp tiên tiến để phân tích dữ liệu lớn sẽ giúp cho doanh nghiệp:
Thấu hiểu insight về hành vi, xu hướng mua sắm của khách hàng từ lịch sử mua hàng, từ đó tạo ra trải nghiệm mua sắm cá nhân hóa hơn
Nâng cao trải nghiệm chăm sóc khách hàng thông qua:
– Xây dựng các chiến dịch tiếp thị, quảng cáo có mục tiêu rõ ràng
– Dự đoán xu hướng thị trường, nhu cầu của khách hàng
– Đáp ứng tốt hơn nhu cầu của khách hàng bằng cách cải thiện thiết kế sản phẩm, gia tăng giá trị khách hàng trọn đời
Cải thiện chuỗi cung ứng thông qua:
– Theo dõi dữ liệu nhà cung cấp theo thời gian thực
– Ngăn chặn sự cố thiết bị thông qua bảo trì dự đoán
– Tối ưu hóa mức hàng tồn kho
– Nghiên cứu phân tích mô hình vận tải
Đọc thêm:Kế hoạch phục hồi sau thảm họa là gì và vì sao nó lại quan trọng?
Tối ưu hóa quy trình tài chính thông qua:
– Xác định các khoản chi tiêu không cần thiết
– Phân bổ nguồn lực hiệu quả hơn
– Nâng cao hiệu quả đầu tư
– Đánh giá rủi ro nhằm xây dựng hệ thống giám sát chặt chẽ hơn và các chiến lược ứng phó phù hợp
– Tự động hóa các công việc thủ công, lặp đi lặp lại
– Giảm chi phí hoạt động và tối đa hóa lợi nhuận
– Tuân thủ tốt hơn các yêu cầu pháp lý đang thay đổi
Dữ liệu lớn được lưu trữ và xử lý như thế nào?
Việc lưu trữ và xử lý dữ liệu lớn đòi hỏi một kiến trúc vững chắc và đặt biệt với nhiều thành phần như sau.
Thành phần lưu trữ cốt lõi
Hạ tầng lưu trữ dữ liệu lớn đòi hỏi một vài thành phần quan trọng:
– Các hệ thống tệp phân tán: Áp dụng các giải pháp như Hệ thống tệp phân tán Apache Hadoop (HDFS) [3] để lưu trữ khối lượng dữ liệu phân tán cực lớn đồng thời linh hoạt mở rộng khi dung lượng gia tăng.
– Cơ sở dữ liệu NoSQL: Các nền tảng như MongoDB sắp xếp các tài liệu thành những tập hợp dựa trên giá trị.
– Hồ dữ liệu (data lake): Các kho chứa dữ liệu siêu khổng lồ, cho phép lưu trữ dữ liệu gốc ở định dạng nguyên thủy nhất, đảm bảo tính toàn vẹn cho các nhu cầu phân tích trong tương lai.
Đọc thêm:Data Lake là gì? Phân biệt Data Warehouse và Data Lake
Khung xử lý
Để xử lý dữ liệu lớn, doanh nghiệp có thể áp dụng nhiều phương pháp và nền tảng khác nhau:
1. Xử lý theo cụm (batch processing)
– Xử lý các nguồn dữ liệu tĩnh thông qua các tác vụ/ quy trình chạy nền liên tục
– Lọc và kết hợp dữ liệu để phân tích
– Chuẩn bị dữ liệu cho các hoạt động xử lý, phân tích
2. Xử lý ngay trong thời gian thực (Real-time processing)
– Phân tích dòng dữ liệu ngay khi nhận được
– Đưa ra thông tin giá trị tức thì từ dữ liệu mới
– Dùng các công nghệ xử lý luồng để quản lý dữ liệu liên tục
Các phương pháp tiếp cận có cấu trúc
Doanh nghiệp có thể áp dụng một trong hai mô hình kiến trúc chính sau để xử lý dữ liệu lớn:
1. Kiến trúc Lambda
Phương pháp này xây dựng hai lộ trình cho dòng chảy dữ liệu, mỗi lộ trình phục vụ một mục đích khác nhau:
– Tầng xử lý theo cụm (batch layer, luồng “lạnh”): lưu giữ dữ liệu thô và chạy xử lý hàng loạt
– Tầng tốc độ (speed layer, luồng “nóng”): phân tích dữ liệu gần như tức thì
Dữ liệu thô không thay đổi để hệ thống có thể phân tích hoặc tận dụng lại khi có nhu cầu hoặc khi mô hình phân tích phát triển.
2. Kiến trúc Kappa
Một lựa chọn tinh gọn hơn, với ưu điểm nổi bật là:
– Xử lý mọi dữ liệu thông qua một kênh duy nhất
– Áp dụng các hệ thống xử lý luồng (stream processing)
– Thuận tiện cho việc bảo trì và giảm bớt phức tạp
Tối ưu hóa quy trình xử lý
Một số phương pháp nâng cao hiệu quả xử lý dữ liệu lớn bao gồm:
– Điện toán trong bộ nhớ (in-memory computing): Lưu trữ dữ liệu trên RAM thay vì ổ đĩa giúp tăng đáng kể tốc độ xử lý, cho phép phân tích dữ liệu liên tục, tức thì.
– Phân mảnh dữ liệu: Các cơ sở dữ liệu đồ sộ được phân tách thành các phần nhỏ hơn, tạo thuận tiện để xử lý song song và cải thiện hiệu suất.
– Lập chỉ mục (index): Việc tối ưu hóa chỉ mục giúp tăng tốc độ trả kết quả truy vấn và đẩy nhanh quá trình tìm kiếm dữ liệu.
Mô hình cơ sở hạ tầng
Cơ sở hạ tầng dữ liệu lớn có thể được thiết lập theo nhiều cách khác nhau:
– Nội bộ (On-prenises): Trung tâm dữ liệu của riêng doanh nghiệp, mang lại quyền kiểm soát cơ sở hạ tầng tuyệt đối.
– Nền tảng đám mây (Cloud-based): Cơ sở hạ tầng như một dịch vụ (IaaS) cung cấp các tài nguyên linh hoạt, được quản lý bởi nhà cung cấp nền tảng.
– Kết hợp (Hybrid): Sự kết hợp giữa tài nguyên nội bộ và đám mây tạo ra sự cân bằng giữa kiểm soát và khả năng thích ứng.
Hệ thống lưu trữ dữ liệu lớn tối ưu cần sở hữu khả năng xử lý khối lượng dữ liệu không giới hạn, hỗ trợ truy cập và cập nhật thông tin ngẫu nhiên, đồng thời chấp nhận mọi định dạng dữ liệu. Để giải quyết thách thức về dung lượng, các hệ thống này thường được thiết kế với kiến trúc phân tán độc lập, tức là dữ liệu được phân tán trên các node mạng.
Lựa chọn giải pháp lưu trữ dữ liệu lớn phù hợp
Để xử lý khối lượng dữ liệu khổng lồ, doanh nghiệp cần một hệ thống lưu trữ tương xứng. Tin vui là thị trường đang tràn ngập các giải pháp tiềm năng. Mỗi lựa chọn được nhắc đến dưới đây đều có những ưu điểm riêng, được thiết kế để đáp ứng chính xác nhu cầu và giới hạn hoạt động của bạn.
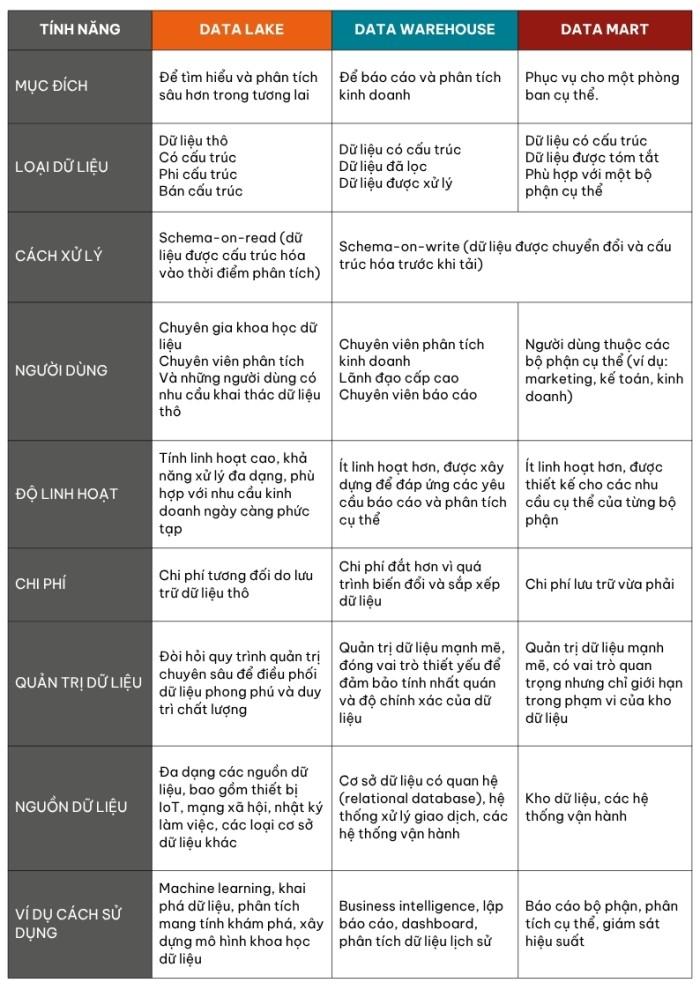
Data lake vs data warehouse vs data mart
Hồ dữ liệu data lake hoạt động như những kho lưu trữ siêu khổng lồ cho dữ liệu thô. Doanh nghiệp có thể lưu trữ thông tin phi cấu trúc, bán cấu trúc và có cấu trúc mà không phải lo ngại về giới hạn lưu trữ. Những kho lưu trữ dạng này thường hỗ trợ nhiều phương pháp phân tích, từ machine learning đến trực quan hóa. Data lake phù hợp nhất cho mục đích phân tích thử nghiệm và tìm kiếm các xu hướng mới trong dữ liệu.
Đọc thêm:Đừng để data lake của doanh nghiệp trở thành ‘đầm lầy dữ liệu’
Kho dữ liệu data warehouse tập hợp dữ liệu từ nhiều nguồn khác nhau vào một nền tảng lưu trữ trung tâm nhằm thống nhất chất lượng và định dạng dữ liệu. Thông qua quy trình trích xuất, biến đổi và tải (ETL), data warehouse sẽ tiến hành làm sạch và tái cấu trúc thông tin trước khi lưu trữ theo cách ‘schema-on-write’. Data warehouse hỗ trợ cho:
– Các quy trình phân tích trí tuệ doanh nghiệp (business intelligence)
– Báo cáo hiệu suất chuyên sâu
– Nghiên cứu dữ liệu quá khứ
– Đưa ra quyết định mang tính chiến lược
“Siêu thị” dữ liệu data mart hoạt động như các phiên bản thu nhỏ của data warehouses, lưu trữ các mảnh dữ liệu cho các phòng ban, bộ phận kinh doanh riêng biệt. Các kho lưu trữ chuyên biệt này cung cấp:
– Phân tích nghiệp vụ của từng phòng ban
– Truy cập dữ liệu tại chỗ
– Thông tin kinh doanh chuyên sâu
– Đơn giản hóa quy trình
Lựa chọn lưu trữ đám mây vs lưu trữ tại chỗ
Lựa chọn nên lưu trữ trên đám mây hay lưu trữ tại chỗ ảnh hưởng đáng kể đến khả năng quản lý dữ liệu của doanh nghiệp. Lưu trữ đám mây cho phép doanh nghiệp lưu giữ dữ liệu trên các máy chủ từ xa, mang lại sự linh hoạt và chi phí đầu tư ban đầu thấp do không cần thiết phải đầu tư vào phần cứng.
Đọc thêm:Mọi thứ bạn biết về phần mềm SaaS có thể đều sai
Lưu trữ tại chỗ giữ dữ liệu trong cơ sở hạ tầng vật lý của chính doanh nghiệp, nhờ vậy doanh nghiệp cũng sẽ nắm toàn quyền kiểm soát kho lưu trữ cũng như quy trình bảo mật và tuân thủ. Phương pháp này đặc biệt phù hợp với các doanh nghiệp thường xuyên phải xử lý thông tin nhạy cảm hoặc phải tuân thủ các quy định nghiêm ngặt.
Các giải pháp tại chỗ yêu cầu vốn đầu tư ban đầu cao và chi phí duy trì định kỳ. Dù vậy, đây vẫn là ưu tiên hàng đầu cho các doanh nghiệp thường chịu sự quản lý nghiêm ngặt, các nhà thầu quốc phòng và các đơn vị cung cấp dịch vụ y tế.
Các yếu tố chính cần cân nhắc khi lựa chọn giải pháp lưu trữ dữ liệu lớn
Doanh nghiệp nên đánh giá cẩn thận các yếu tố sau để lựa chọn đúng giải pháp lưu trữ tối ưu nhất:
Dung lượng và loại dữ liệu
– Doanh nghiệp của bạn có những yêu cầu cụ thể nào về việc lưu trữ dữ liệu?
– Tỷ lệ giữa dữ liệu có cấu trúc và không có cấu trúc hiện nay là bao nhiêu? Điều này sẽ ảnh hưởng đến việc lựa chọn giải pháp như thế nào?
– Doanh nghiệp thường phân tích dữ liệu như thế nào? Mô hình khối lượng công việc phân tích điển hình trong doanh nghiệp là gì? Quy trình phân tích sẽ ảnh hưởng đến hệ thống lưu trữ ra sao?
Yêu cầu về bảo mật
– Doanh nghiệp cần phải đáp ứng những yêu cầu, quy định tuân thủ cụ thể nào?
– Dữ liệu có những cấp độ nhạy cảm nào?
– Những đối tượng nào cần được cấp quyền truy cập dữ liệu? Những cơ chế kiểm soát truy cập nào là cần thiết?
Cân nhắc hiệu suất:
– Tốc độ cần thiết để xử lý dữ liệu lớn là bao nhiêu?
– Mức độ trì hoãn phân tích mà doanh nghiệp có thể chịu được?
– Băng thông (bandwidth) khả dụng của công ty là gì, tác động như thế nào đến việc xử lý và chuyển giao dữ liệu?
Chi phí:
– Nguồn vốn đầu tư hiện có cho việc triển khai giải pháp mới là bao nhiêu?
– Giới hạn ngân sách cho việc triển khai, bảo trì và hỗ trợ lâu dài là bao nhiêu?
– Chiến lược phát triển kinh doanh là gì?
Lựa chọn giải pháp đúng đắn định hình cách doanh nghiệp có thể quản lý và phân tích dữ liệu lớn một cách hiệu quả. Việc đánh giá cẩn thận nhu cầu kinh doanh, các hạn chế về kỹ thuật và dự định phát triển trong tương lai hỗ trợ các doanh nghiệp chọn được những giải pháp đáp ứng được mục tiêu và nhu cầu hoạt động của họ.
Dữ liệu lớn đánh dấu một bước ngoặt trong cách quản lý, xử lý và khai thác thông tin, chuyển hóa những khối lượng dữ liệu khổng lồ thành những insight giá trị. Để xử lý hiệu quả dữ liệu lớn, điều cần thiết là phải có các giải pháp lưu trữ phù hợp, các biện pháp bảo mật vững chắc, quy trình kiểm soát chất lượng nghiêm ngặt, tỉ mỉ nhằm bảo vệ quyền riêng tư và độ chính xác của dữ liệu.
Tại TRG International, chúng tôi tự hào giới thiệu Infor OS – nền tảng điều hành doanh nghiệp tân tiến, tích hợp nhiều chức năng phong phú, trong đó nổi bật là Infor Data Fabric – một kho lưu trữ dữ liệu hiện đại, được thiết kế để đáp ứng mọi yêu cầu về dữ liệu lớn.
Kết hợp cùng Infor OS, bộ giải pháp toàn diện này cho phép doanh nghiệp bạn tối ưu hóa hoạt động, tự động hóa các công việc thủ công và khai thác những công nghệ tiên tiến nhất chỉ bằng vài cú nhấp chuột.
Tải ngay borchure Infor OS để tìm hiểu thêm về giải pháp công nghệ hiện đại này!

Nguồn:
1. https://www.coursera.org/articles/5-vs-of-big-data
2. https://www.geeksforgeeks.org/top-7-big-data-applications-with-examples-in-real-life/
3. https://codilime.com/blog/big-data-infrastructure-essentials-and-challenges/
